Raft explained
Explaining the Raft distributed consensus algorithm in a hopefully easier to understand way!
In this article, I will be dong something a little different! Most of my articles up until now have been very fun projects of completely random things that I have enjoyed doing, but with the way that life seems to be going, there are less and less fun random things that I do. However, there are things in my work that I am still enjoying just as much, and I'd like to still keep blogging and sharing some of that stuff into the void.
So today, I'll be giving my own condensed explanation of Raft! Raft is a system to implement replicated state machines, and is loved/hated by distributed systems students around the world. I wrote this to help me with my own distributed systems class, and I hope it will help other students in the future! My general philosophy was to always outline why everything in Raft works, which should make it much easier to debug issues. I'd also like for it to be completely possible to implement Raft yourself, after having read this article.
This article might have some mistakes! I've heard that Raft requires a lot of care and is quite error prone. I think this article should be all good after several rereads, but if there are any errors please let me know!
But before we get started:
What is a state machine?
A state machine is any system which:
- keeps track of some state
- accepts input commands. These input commands will:
- deterministically change the state of the system (based only on the current state and the input command)
- be able to potentially produce a deterministic response (based only on the current state and the input command)
This definition sounds complicated, but if it is a computer program, it is probably a state machine. For example, databases can be state machines: their state is all the data currently in the database, and input commands can update records in the database and read records in the database, changing and reading the state deterministically. As such, a state machine is a pretty broad abstraction for a lot of computer programs.
What is a replicated state machine?
A replicated state machine, to an outside user, looks just like a regular state machine. It is still a system that can keep track of a state and accept input commands. However, in a replicated state machine, the code for the state machine runs on multiple (\(N\)) servers, each of which keeps their own copies of data relating to the state machine. This is for fault tolerance: if a minority of the servers go down, the overarching state machine system should still be usable by clients that are issuing input commands.
This creates a whole new slew of issues, mostly surrounding the issue of how do we ensure that all state machines are in sync on all servers? We don't want it to be possible for some servers to hold a different state to other servers, as this would mean that they would respond differently to a sequence of input commands.
We typically want a replicated state machine to have the following properties:
- Safety under non-Byzantine conditions: Safety means that it is not possible for the system to produce an incorrect response: if a command leads to a change in state of the whole system, that change in state cannot be lost, for example. Non-Byzantine conditions means any form of issues *except* for any of the \(N\) servers being compromised and behaving in an unexpected fashion. Non-Byzantine conditions includes:
- servers failing
- The network failing, or having delays
- Messages on the network being reordered
- Availability if the majority of servers are operational: This means that the system of servers as a whole can accept input commands and respond to them so long as a strict majority of servers are working and can communicate with each other
- No dependence on timing: This allows the system to support very long message delays and faulty clocks
- No "waiting for stragglers": If a minority of servers are acting slowly and not responding to network messages, the overall system will not be affected and will still quickly respond to input commands.
How does Raft work?
Raft is a "consensus algorithm", which means that it is an algorithm to ensure that all of the servers can reach some shared consensus on what the state of the system is, no matter what is happening on the network (servers failing at arbitrary times, network failures and delays, packet reordering on the network). This turns out to be quite a delicate system, but we will build it up from scratch, one piece at a time.
Note: what is an RPC?
This article (and the Raft paper) refer to RPCs. For the reader, RPCs are "remote procedure calls", and we can treat these as a black box that allows us to call a function on another server on the network, and to return the results of this function call over the network. All network communication in Raft is done on the RPC layer of abstraction; there is a lot more networking and systems "stuff" happening to make RPCs work, but languages like Go support having remote procedure calls as a black box that you can use natively in the language, so we will leave this as a black box too!
OK! Now we can finally get onto Raft.
Part 0: leaders
Leaders are an idea that we'll come back to later. Raft tries to have a single server in the cluster act as the leader. It is the one that receives new input commands to the replicated state machine, and it is thus responsible for making sure that these commands make it to all other servers in the cluster.
We will revisit how servers become leaders later: for now, let's just set out some facts about how leaders work and then understand how we can get these properties later:
- Any server can be one of three things: a follower (which recognizes that some other leader is out there), a leader or a candidate (who no longer recognizes the current leader, and tries to become leader)
- Each server views time as divided into strictly increasing terms, identified by a single number.
- In any term, at most one server can be leader, and this server is recognized as a leader by a majority of the servers in a cluster.
- If a leader dies for any reason, the servers will work together to transition elect a new leader
Now, if any two servers are talking to each other, it makes sense that they should agree on what the current term is.
- If a server thinks it is in term \(a\) but it receives a request from a server in term \(b > a\), it must realize that some new leader has been elected, and it is living in the past. This server will thus update what it thinks the current term is to \(b\), and will demote itself to follower (as the higher term implies that some other leader is out there, or is about to be elected)
- If a server thinks it is in term \(a\) but it receives a request from a peer server in term \(b < a\), it disregards anything that \(b\) is saying, as it is more out of date. Additionally, in its reply to the peer server, it will tell the peer that the cluster is in a new, larger term, so that the peer can update what term it currently is.
In pseudocode, this logic looks like this:
def verify_term(self, term_number: int):
if self.term < term_number:
# incoming request is from a server more up to date than us
self.term = term_number
if self.state == State.LEADER or self.state == State.CANDIDATE:
self.state = self.FOLLOWER
return True, Response.OK
elif self.term == term_number:
# incoming request is from a server in line with us
return True, Response.OK
elif self.term > term_number:
# incoming request is from a server behind us, ignore it
# try to respond
return False, Response.UpdateTermRequest(self.term)
And then all RPCs would have this bit of code at the top:
def AnyRPC(self, args, term_number):
ok, response = self.verify_term(term_number)
if not ok:
return response
OK! Now we're at the point where all communications are occurring between servers in the same term, and in this term (hopefully) a leader is elected!
Part 1: logs and log replication
After a leader is elected, the full system can now start servicing input commands. For a client to interact with the system, it must interact with the leader (if it reaches a different server, the server will send it the address of the server it thinks it is currently the leader). When a leader receives a command from a user, it cannot immediately execute it. This is because it needs to make sure that the data is replicated and recorded elsewhere (on the other servers) in case the leader crashes. If it doesn't record this data, a situation like the one seen in the diagram below can happen.
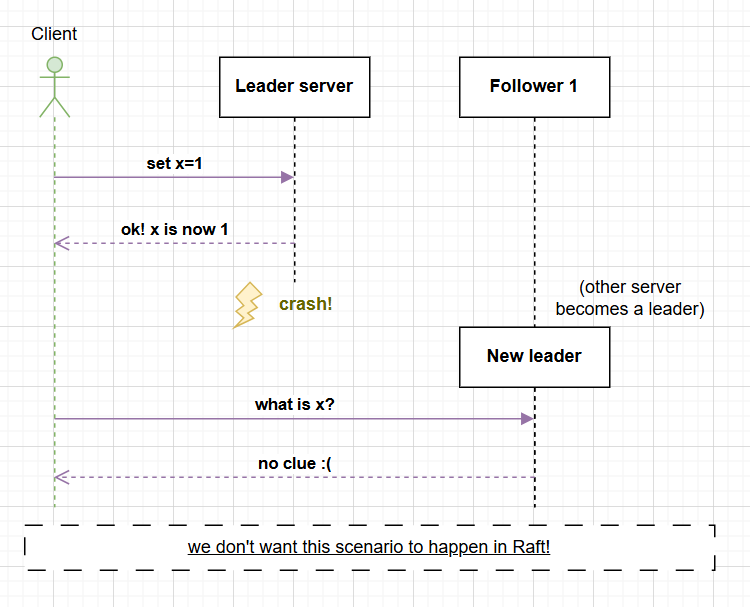
To help rectify this issue, Raft maintains a log on each server. This log is a way for each server to store what it thinks the history of the commands seen so far is. A log is just an array, and it looks something like this:
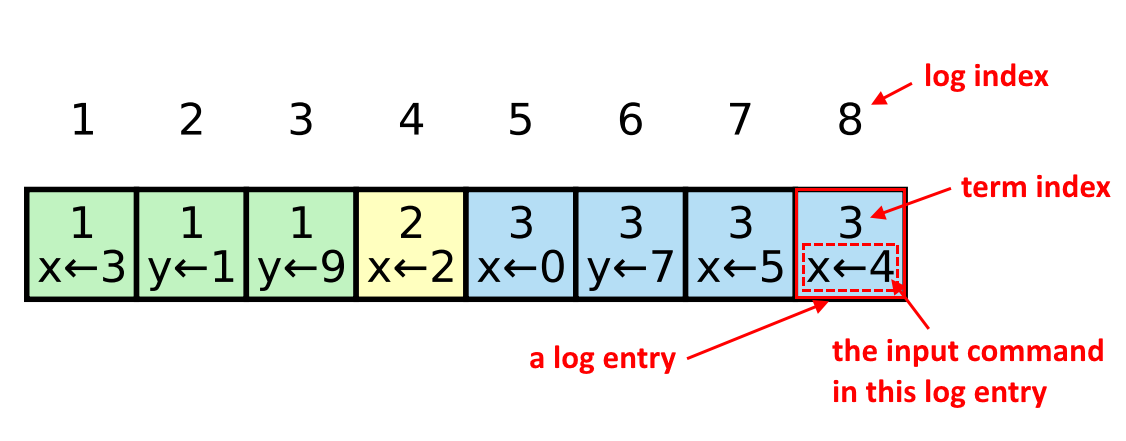
The term index is the term in which this input command was received. The log and term indices of a log entry are important and are often used in reasoning about these log entries, so keep them in mind!
Now, when a leader receives an input command, instead of immediately executing it, it adds it to its own log entry, and then tries to tell a majority of servers to add it to their logs. The RPC that is used to tell other servers to add entries is called `AppendEntries`, and a boilerplate of its signature looks like this:
def AppendEntries(entries: List[InputCommand]):
If an entry makes it to a majority of logs within the term in which that log entry was added (this detail will turn out to be very important later!), we say that the log entry and all log entries before it are committed.
Committed entries: Entries made in term \(i\) can become committed if the leader of term \(i\) replicates the entry on a majority of logs
Committed entries will not be lost in the future and will eventually reach all servers in the cluster. Logs are persistently stored on disk, so even if a server crashes, that log entry will not be lost. These entries are thus safe to execute.
But how do we ensure that all logs look the same up to and including all committed entries? After all, this is a state machine: it's important that everyone executes the same commands in the same order. Naively sending the log entry to followers won't work if the follower logs are out of sync. Additionally, if `AppendEntries` requests are reordered on the network, this could make the follower logs inconsistent with the leader log.
To alleviate this, Raft maintains the following Log Matching Property at all times.
Log Matching Property: If two entries in different logs on different servers have the same index and term, then the logs of both servers are identical up to (and including) the index and term of the matching entries.
We will now build up to how Raft enforces the log matching property. To start off, note another key property:
Leader Append Only: For as long as a server is a leader in its term, it will never remove or modify entries from its log: it will only append to the end of its log
This means that it is never possible for two entries anywhere in the system to have the same index and term but different data. In each term, there is at most only one leader which could possibly mint entries with that term number. As all entries that the leader creates in its term are given increasing indices, and these entries end up in the same indices when they reach logs in other servers, the `(index, term)` pair is sufficient to uniquely identify the entry.
The term and index of a given log entry is enough to uniquely identify its data.
Maintaining the full Log Matching Property turns out to be really easy! We just have the follower perform a consistency check with the leader. In an AppendEntries RPC, the leader will also send the index and term of the log entry before the entries it is trying to append (which we dub the "predecessor entry"). This means that the AppendEntries signature now looks like this:
def AppendEntries(predecessorEntryIndexAndTerm: tuple[int, int], entries: List[InputCommand]):
The follower will try to find this predecessor log entry in its own log, and will append the new entries directly after this log, discarding any pre-existing entries after this shared predecessor in the follower log. If the follower cannot find the predecessor entry, the AppendEntries RPC will fail. This means that the follower did not have the entry before the entries to be appended, and so the leader will try to call AppendEntries, but now from an even older point in the log, with an even older predecessor.
The new implementation of AppendEntries on the follower end now looks like this:
def AppendEntries(predecessorEntryIndexAndTerm: tuple[int, int], entries: List[InputCommand]):
# ommiting the term check logic from the previous component for clarity
# There's a leader in our term, so we must be a follower
self.state = State.FOLLOWER
predIndex, predTerm = predecessorEntryIndexAndTerm
if predIndex >= len(self.log):
# we definitely don't have this entry
return False # indicate failure
# the leader will retry, but with an older
# predecessorEntryIndexAndTerm, which we (the follower)
# might have
if predIndex != -1 and self.log[predIndex].term != predTerm:
return False # indicate failure, same behavior as above
# if we've made it here, we can complete the AppendEntries!
# clear everything after the entry that the leader expects to come before the new entries
self.log[predIndex + 1:] = []
self.log.extend(entries) # Add all elements in entries to the current log.
But why does checking the predecessor entry guarantee the log matching property? We can quite easily prove this through a simple inductive argument:
- Base case: the Log Matching property holds when all logs are empty.
- Inductive step: Suppose that the log matching property holds for all entries. When a new entry with its own unique (index, term) pairing \((i, t)\) is introduced into the system, it gets distributed through the system by the leader of term \(t\). In any AppendEntries calls that the leader makes, the leader and follower agree on a shared predecessor before entry \((i, t)\) and by the inductive hypothesis, all entries before this predecessor. Therefore, the logs will match up to \((i, t)\) when \((i, t)\) is added through the AppendEntries RPC, completing the inductive hypothesis (as the Log Matching property continues to hold for this new entry).Awesome! To wrap things up, let's also quickly look at some pseudocode for how the leader accepts new entries and how it could distribute them. The general gist is that the leader will accept any new commands and add them to its log. Then, whenever it sends an AppendEntries to a server, it will try to start from where it thinks their shared predecessor could be, and it will move backwards if the entry is rejected. To do this, it maintains the index that it thinks is a shared predecessor with each server.
def BeginAddNewCommand(command: CommandData):
"""
Tells the leader to add a new command and start replicating it.
This comes from the user, not any other servers!
"""
self.log.append(InputCommand(term=self.term, index=len(self.log), data=command))
def send_append_entries_loop():
while True:
sleep(0.05) # sleep a bit
for peer in self.peer_servers:
predecessorIdx = peer.predecessorIdx
newIdx = len(self.log) - 1
# This can be run in parallel (think asyncio)
reply = peer.AppendEntries(
predecessorEntryIndexAndTerm = (predecessorIdx, self.log[predecessorIdx].term),
entries = self.log[predecessorIdx + 1:]
)
# perform the standard term check on the reply, omitted
# check that we're still the leader before we do any leader activities
if self.state == LEADER:
if reply.did_append:
# They appended! We have a new shared predecessor as they accepted all our entries
peer.predecessorIdx = newIdx
else:
# They didn't append, try decrementing the predecessor the next time
peer.predecessorIdx -= 1
To help clarify things, here's a picture that should help further clarify some of the ideas in this section:
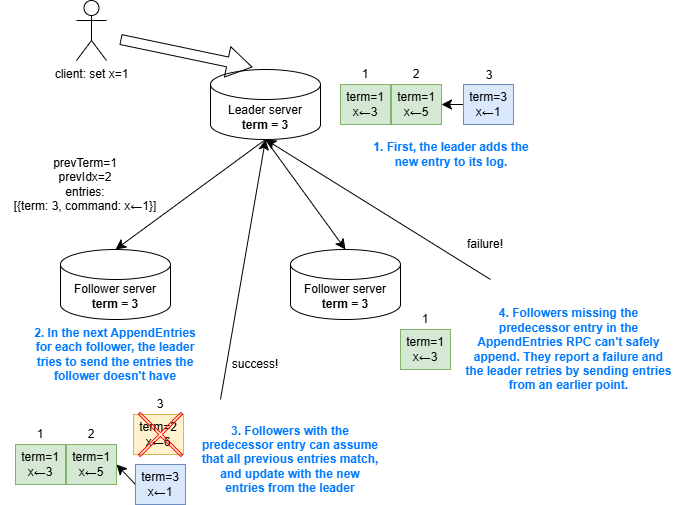
Part 2: Elections
We now have the quite powerful Log Matching property. However, we have a couple of holes left to fill:
- How do we ensure that committed entries never get lost? Note that the AppendEntries RPC totally allows entries to be overwritten, so as things stand, it might be possible for these entries to somehow become "uncommitted".
- How do we actually elect leaders?
It turns out that these things are linked!
Remember the assumptions about leadership we made earlier:
- Any server can be one of three things: a follower (which recognizes that some other leader is out there), a leader or a candidate (who no longer recognizes the current leader, and tries to become leader)
- Each server views time as divided into strictly increasing terms, identified by a single number.
- In any term, at most one server can be leader, and this server is recognized as a leader by a majority of the servers in a cluster.
- If a leader dies for any reason, the servers will work together to transition elect a new leader
Let's get started!
When the system starts, all servers think that they are a follower and will remain a follower for as long as they are getting communications (AppendEntries requests) from a leader. Only leaders are allowed to send these requests, so receiving an AppendEntries "heartbeat" (with the correct term number) tells the receiver that there is some leader currently active in this term. If a follower goes too long without receiving a heartbeat (this period of time is called the election timeout and is randomized between 150-300ms) it will enter the candidate state and will try to become a leader.
To become a leader, the candidate begins by incrementing its term number and entering a new election. The goal of this is to move into the next term. If one server increments its term number and starts sending requests, all other servers that receive requests from this server will increment their own term number. There are a few outcomes of this election:
- Someone else becomes a leader and establishes its status through a heartbeat RPC (AppendEntries, which we will see later)
- In this case, the candidate accepts that it has lost the election and switches to the follower state
- The candidate wins the election!
- In this case, it becomes leader and begins issuing heartbeats (AppendEntries) to the rest of the cluster
- Noone wins this election and the candidate times out
- It then tries to start a new election with a new, incremented term index
To win an election, it calls a RequestVote RPC on the other servers in the cluster. The other servers will vote for servers on a first-come-first-served basis, with each server voting for at most one server in a single term. This means that only one server can reach a majority in a single term as desired. This makes our RequestVote RPC look like this:
# Returns true if we are voting for the requesting server in this term.
def RequestVote(self, requesting_server, term_number: int):
ok, response = self.verify_term(term_number)
if not ok:
return response
if self.votes_by_term.get(term_number) == None:
# we haven't voted for anyone else this term!
# we can vote for this server
self.votes_by_term[term_number] = requesting_server
if self.votes_by_term[term_number] == requesting_server:
# the server asking for a vote is the one we are voting for in this term
return True
else:
# we are already voting for someone else
return False
Note a very important point: a server needs to persist which server it's voting for in the current term to disk. This is essential to ensure that each server only votes once. Otherwise, a server could vote for a candidate A, crash and forget it voted for A, and then vote for B in the same term. This could lead to two leaders, which would be disastrous!Besides that, pretty simple! And let's also talk about the main loop that starts elections:
def run_election(self):
self.state = State.CANDIDATE
# These should be sent out in parallel! But we use a for loop to make this
# easier to read
votes = 0
for server in NETWORK_SERVERS:
# This check lets us end the election early if we are kicked out
# of candidate state by any elected leader sending AppendEntries RPCs.
if self.state == State.CANDIDATE:
if server.RequestVote(self.server_id, self.term_number):
votes += 1
if votes >= NETWORK_STRICT_MAJORITY:
self.state = State.LEADER # And start sending heartbeat RPCs!
else:
# We failed to win the election.
# We can still try again though!
self.state = State.FOLLOWER
def election_loop(self):
while True:
# Sleep for a random amount of time
sleep(random_between(minElectionTimeout, maxElectionTimeout))
if !self.leaderAlive:
# start an election!
self.run_election()
else:
# do nothing, but set self.leaderAlive = false
# This means we will need to receive another heartbeat to keep
# recognizing the current leader
self.leaderAlive = false
Before we move on, let's discuss some things that we should be worried about and justify why we shouldn't be too worried about them:
Q: How do we prevent split votes? If multiple servers become candidates at the same time and issue different RequestVote RPCs, the votes for that term could be split.
A: We don't! In the case of a split vote, one of the candidates will eventually time out and try and start a new election. The use of randomized timeouts is intended to make split votes unlikely: it is most likely that one server will time out a decent bit before the others, and will quickly win the election before other servers even get a chance to become candidates.
Q: So does this mean that a server can singlehandedly "kill" a leader, by becoming a candidate and incrementing the term number?
A: Yes! If any follower sees that it has not received heart beats for a while, it will become a candidate and start a new term. The term verification step, when run on the leader, will cause the leader to switch to follower state. As a thought experiment, we can design a very inconvenient network where for each server A, there is at least one other server B for which A -> B communication is impossible, but B -> A communication is just fine. Each time a leader is elected, the server which it can't communicate with will not receive heartbeats, timeout and will start a new election, killing the old leader. In Raft, it is important to thus carefully choose timeouts so that leaders that keep dying isn't too bad of an issue. It is important to choose an election timeout such that
$$\text{broadcastTime} << \text{electionTimeout}$$
The broadcastTime is the average time for a single server to send an RPC to all other servers in parallel and receive a response. This inequality means that even if servers keep timing each other out, they will be able to serve many requests and broadcast them to the whole cluster in this time.
Before we move onto the next section, let's review what we've accomplished with the leadership system:
- At all times, there is at most one effective leader that is recognized by the majority of servers
- True! For a server to be a leader, it must have received votes from a majority of servers in the current term. It is possible that another server in an older term continues to think that it is a leader, but the majority of servers will not recognize it
- The period of time where a server is a leader is called a term. Terms are numbered with unique increasing ids
- (We've already discussed at length how term indices work, and how the term verification keeps the full cluster up to date on what the current term is)
- When there is no leader, servers work to quickly elect a new leader
- The election timeout will quickly start an election for a new leader as desired
Election restrictions
We are very nearly done with elections! However, we still never dealt with this problem:
How do we ensure that committed entries never get lost? Note that the AppendEntries RPC totally allows entries to be overwritten, so as things stand, it might be possible for these entries to somehow become "uncommitted".
For reference, recall the definition of a committed entry:
Committed entries: Entries made in term \(i\) can become committed if the leader of term \(i\) replicates the entry on a majority of logs
To prevent committed entries from disappearing, Raft enforces the Leader Completeness Property.
Leader Completeness: If a log entry is committed in a term, the committed entry will be present in all leaders of higher numbered terms.
It turns out that one modification is sufficient to make the whole system work: servers can only vote for leaders with logs that are more up to date than them. Here, a log (log A) is more up to date than a different log (log B) if and only if:
- The last entry in log A is from a later term than the last entry in log B
- The last entries in logs A and B are in the same term, but log A is longer.
We will now see why this voting rule ensures the Leader Completeness property (committed entries are always present in all future leaders). Suppose that an entry E from term \(i\) makes it to a majority of servers in term \(i\). On term \(i + 1\), it is not possible for a server that does not have entry E to become leader.
- If the candidate server has its last entry from a term before term \(i\), it definitely can't become a leader. As a majority of servers contain E, the majority of servers have a later last term (at least \(i\)) than the candidate, and it is therefore not possible for this candidate to win the election
- If the candidate server has its last entry from term \(i\), then by the Log Matching property, it will contain E if and only if the length of this log is \(\geq\) the index of E, as in a single term, all log entries are added one by one in order as enforced by the consistency check. If the candidate server does not contain E but E is committed, then the majority of servers will have logs longer than the candidate server, and thus the candidate will not be elected.
So now, committed entries are present in all future leaders. In each term, a leader is going to try and bring its followers logs in line with its log, which means it will preserve these committed entries in its AppendEntries calls too. Therefore, committed entries are guaranteed to persist forever!
Common misconception: entries that make it to a majority of servers are committed. It turns out to be a very important detail that an entry made in term \(i\) is only committed if the leader of term \(i\) is the one to replicate it on a majority of logs. A counterexample is provided in the original Raft paper, with the following diagram:
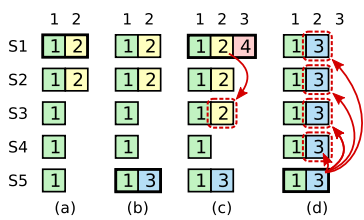
Here's how we could get to this state:
- S1 is elected the leader of term 2, and begins to replicate log entry 2 to S2.
- S1 crashes, and S5 is elected the leader of term 3. It accepts a new log entry in term 3, but crashes and fails to replicate it.
- S1 becomes elected the leader of term 4, and tries to continue replicating its log. Log entry 2 thus makes it to term 3. At this point, the entry with term 2 is in a majority of servers!
- However, S5 has an entry from a higher term (term 3), and so it can still be elected leader by a majority of the cluster in term 5. In bringing the logs into line, it overwrites the existing entries with term 2!
However, if log entry 2 also made it to S3 in term 2 (in the first picture), it would be committed, as it would no longer be possible for S5 to be elected the leader of term 3 as S5 would no longer be able to receive a majority of votes.
Here's a picture showing some of the stuff covered under voting:
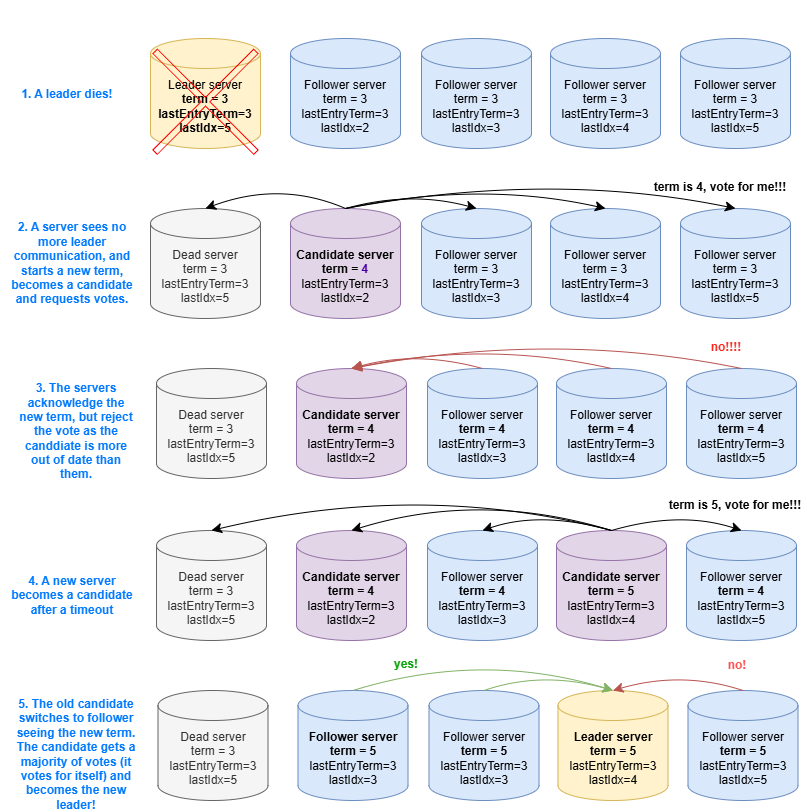
Part 3: How do we actually know when things are committed?
Remember that the whole point of this system was to make a replicated state machine. So far, we've managed to make logs, and we know that once a log makes it to a majority of servers in a term, a majority of the servers agree on the logs up to that point. Ideally, the servers should be perfectly ready to actually execute these committed entries as commands in their state machines.
But how do the servers know when their entries are committed? That is the subject of this section.
The general strategy to do this is to have leaders determine when entries from their term are committed, and to forward this information to their followers.
All servers maintain a `commitIndex` variable which is the latest entry that they know to be committed. In the AppendEntries RPC, the follower returns a success result if they successfully appended the entries to their log. During its term, the leader maintains the latest entry they know to be replicated on each of the follower logs, and this is updated each time an AppendEntries returns a "success" result. This is monotonically increasing and can never go backwards as logs are persisted to disk.
Now, when a majority of servers have replicated an entry from the current term, the leader will know it to be committed, and can safely execute this entry.
To inform the followers, the leader also sends to its followers its own `commitIndex` with all AppendEntries RPCs. After a successful AppendEntries, if a follower determines that the leader's `commitIndex` is greater than its own, it updates its own `commitIndex` to match the leaders `commitIndex` or to be latest entry in the follower log, whichever is earlier.
Now, all servers can know when entries get committed, and thus maintain their own state machines!
Future parts
This article is a bit less cool in my opinion compared to some of the other things on this site, and is definitely not original. However, I hope it helps some people understand Raft better! For me personally, writing this article out before I tackled my own implementation, and reasoning really carefully about the correctness of everything, made my own implementation quite easy and I ended up having to wrestle with almost no bugs (at least for now...). I hope it can help some other people out there!
In the future if I have more time, I'd like to talk about snapshotting and cluster membership changes, but I haven't gone ahead and read those myself yet. Maybe I'll edit this in the future!
Please let me know if there are any bugs or errors with this article!